
In the past, the evolution of network-based storage was not really a problem for network engineers: the network was fast and the spinning hard drives were slow. Natural network upgrades to 10Gb, 40Gb, and 100Gb Ethernet were more than sufficient to meet the networking needs of storage systems.
But now, with the introduction of ultra-fast solid-state disks (SSDs) and Non-Volatile Memory Express (NVMe), this is no longer true! Storage teams now have the ability to potentially saturate the network with incredibly fast devices.
Network-based storage (SANs) using NVMe technology – known as NVMe over Fabric (NVMe-oF) – present significant challenges for the network. And network engineers need to take a close look at this new generation of storage to understand what is different, and how they can meet the performance requirements of truly high-speed storage.
This is the first post in a series of two dedicated to Non-Volatile Memory Express (NVMe), NVMe-over-fabric (NVMe-oF) and Remote Direct Memory Access (RDMA). A second post about and RDMA over Converged Ethernet (RoCE) and how to configure RoCEv2 on the Cisco Nexus 9k series can be found here.
What is NVMe?
Introduction
The purpose of this post is to give a generic overview of the NVMe and NVMe-oF main concepts and to show you the different network fabrics and protocols you may encounter as network engineer. I do not pretend to explain here all the specifications of NVMe and NVMe-oF in details. If you want to learn more about NVMe, I have put at the end of this post a series of links that should be of interest to you.
Where NVMe comes from and how it differs from SCSI
Until recently, storage systems have been based on Hard Disk Drives (HDDs) spinning media with magnetic platters and moving heads that have been the logical progression of a technology more than 60 years old. As the drive technology advanced with faster and smaller devices, the storage industry coalesced around a model of a drive controller connected to HDDs using a parallel or serial bus, such as SAS (Serial Attached SCSI) or SATA (Serial ATA). This well-known and interoperable technology chain from disk drive to bus to controller to computer is well-balanced for performance – so long as the disk drives act like traditional HDDs.
The introduction of Solid-State Drives (SSDs), created a strong imbalance in the world of storage. Suddenly, disk drives could offer RAM-like performance with very low latency and transfer rates in excess of 20 Gbps. The first real commercial deployments of these SSD drives were as drop-in replacements for HDDs in traditional storage systems. SSDs provided higher speed, lower latency, less heat and less power consumption. And no need to re-engineer existing well-known and widely-deployed hardware. They were a win-win for the storage industry.
However, simply putting SSDs into existing storage systems has a drawback: it doesn’t take full advantage of the potential performance increase of the underlying technology. To really benefit from the potential of SSD devices requires a rethinking of the way that storage systems connect to servers. Storage vendors tried several approaches in designing specifically for SSD-based storage, and the ones that caught the most traction in the industry were based on connecting storage devices directly to the PCI Express (PCIe) bus. After multiple proprietary devices were built, the storage and server industry came together in 2011 to create NVMe: Non-Volatile Memory Express.
NVMe is a protocol, not a form factor or an interface specification. NVMe differs from other storage protocols because it treats the SSD devices much more like memory than hard drives. The NVMe protocol is designed from the start to be used over the PCIe interface, and thus connect almost directly to the CPU and memory subsystems of the server. In multi-core environments, NVMe is even more efficient, because it allows each core to independently talk to the storage system. With more queues and deeper queue depth in NVMe, multiple CPU cores can keep the SSDs busy, eliminating even internal bottlenecks to performance. NVMe is a NUMA-aware protocol, taking advantage of the advances in memory subsystem design in newer CPUs. Overall, storage with SSDs and the NVMe protocol can deliver dramatically higher I/O Per Second (IOPS) and lower latency than the same SSDs using SATA or SAS.
From SCSI to NVMe, in brief
SCSI
- SCSI treats storage as devices (tape drives, disk drives, scanners, etc.)
- Requires an adapter that “speaks” SCSI to translate CPU desires into device capabilities.
- Creates a 1:1 relationship between host and storage.
- Works in single queue model: one single queue with up to 64 commands per queue.
Then, mechanical disk drives evolves to solid state drives (SSDs) or flash:
- Flash expose the limitations of SCSI, because flash does not rotate, there is nothing “mechanical” to wait on. So, there is not anymore any latency time of a one command / one queue system.
- Also flash requires far fewer commands than SCSI provides.
- At the end, flash can be considered is like a PCIe RAM. This is where NVMe comes from.
NVMe
- NVMe treats storage as memory.
- CPU can talk to memory natively: no adapter needed.
- Creates many-to-many relationship between host(s) and target(s)
- Works in multi-queues model: 64K queues with up to 64K commands per queue.
In summary, we can say NVMe allows hosts to fully exploit the levels of parallelism possible with modern SSDs. As a result, NVMe reduces the I/O overhead and brings many performance improvements relative to previous logical-device interfaces, including multiple long command queues, and reduced latency. SCSI and other previous interface protocols were developed for use with far slower hard disk drives where a very lengthy delay, relative to CPU operations, exists between a request and data transfer, where data speeds are much slower than RAM speeds, and where disk rotation and seek time give rise to further optimization requirements.
NVMe Definition and Specifications
You can find the official definition of on the NVM Express organization website: https://nvmexpress.org/ – here is an excerpt:
NVM Express™ (NVMe™) is a specification defining how host software communicates with non-volatile memory across a PCI Express® (PCIe®) bus. It is the industry standard for PCIe solid state drives (SSDs) in all form factors (U.2, M.2, AIC, EDSFF). NVM Express is the non-profit consortium of tech industry leaders defining, managing and marketing NVMe technology. In addition to the NVMe base specification, the organization hosts other specifications: NVMe over Fabrics (NVMe-oF™) for using NVMe commands over a networked fabric and NVMe Management Interface (NVMe-MI™) to manage NVMe/PCIe SSDs in servers and storage systems.
The NVMe specification was designed from the ground up for SSDs. It is a much more efficient interface, providing lower latency, and is more scalable for SSDs than legacy interfaces, like serial ATA (SATA). The first part of the specification is the host control interface. The NVMe architecture brings a new high performance queuing mechanism that supports 65,535 I/O queues each with 65,535 commands (referred to as queue depth, or number of outstanding commands). Queues are mapped to CPU cores delivering scalable performance. The NVMe interface significantly reduces the number of memory-mapped input/output commands and accommodates operating system device drivers running in interrupt or polling modes for higher performance and lower latency. The NVMe specification also contains host-to-device protocol for SSD commands used by an operating system for: read, write, flush, TRIM, firmware management, temperature, errors and others.
Then, the current versions of the NVMe, NVMe-oF and NVMe-MI specifications are also available on the NVM Express organization site, here: https://nvmexpress.org/developers/
NVMe over Fabrics (NVMe-oF)
The NVMe protocol is not limited to simply connect a local flash drive inside a server, it may also be used over a network. When used in this context, a network “fabric” enables any-to-any connections among storage and servers elements. NVMe over Fabrics (NVMe-oF) are enabling organizations to create a very high performance storage network with latency that rival direct attached storage. As a result, fast storage devices can be shared, when needed, among servers. Think of NVMe over fabric as an alternative to SCSI on Fibre Channel or iSCSI, with the benefit of a lower latency, a higher I/O rate and an improved productivity.
The servers (or other hosts) talk to the NVMe storage over the network fabric directly, or indirectly via a controller. If the storage solution uses a controller, then the controller talk to it’s own storage targets, via NVMe-oF like a daisy-chain, or via another proprietary or non-proprietary solution. It depends of the storage vendor implementation and choices.
NVMe-oF transport protocols
As network engineer, you need to know the three official transport bindings to operate NVMe-oF in your data centers:
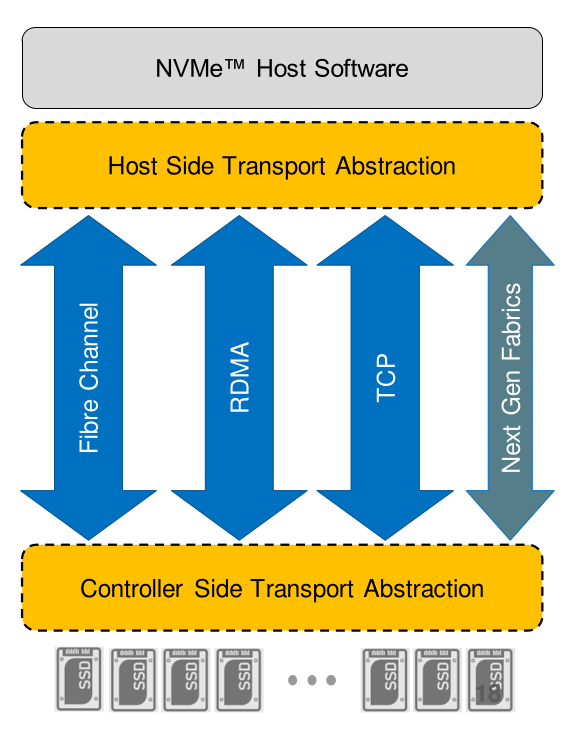
- Fibre Channel (NVMe/FC) – NVMe initiators (hosts) with for example Broadcom/Emulex or Marvell/Cavium/QLogic Host Bus Adapters (HBAs) can access NVMe targets over dedicated Fibre Channel (FC) fabrics or Fibre Channel over Ethernet (FCoE) fabrics. The Fibre Channel Transport maps NVMe “control-plane” capsules (commands and responses) and “data-plane” data messages onto Fibre Channel frames using the NVMe over FC protocol (FC-NVMe) via FCP Exchanges.
- TCP (NVMe/TCP) – NVMe hosts and controller(s) communicate over TCP by exchanging NVMe/TCP Protocol Data Units (NVMe/TCP H2C and C2H PDUs). An NVMe/TCP PDU may be used to transfer the NVMe “control-plane” capsules (commands and responses) and “data-plane” data. As NVMe/FC, this is a “messages only” data transfers.
- Remote Direct Memory Access (NVMe/RDMA – supported on InfiniBand or Ethernet networks) – RDMA is a host-offload, host-bypass technology that allows an application, including storage, to make data transfers directly to/from another application’s memory space. The RDMA-capable Ethernet NICs (rNICs) or the HCA in the InfiniBand world – not the hosts – manage reliable connections between NVMe source and destination(s). With RDMA, the NVMe “control-plane” capsules (commands and responses) are transferred using messages, and the “data-plane” (the data) are transferred using memory semantics like RDMA read/write operations. You have to see the data-plane part like PCIe direct memory operations.
In addition to these three “official” solutions, there are other proprietary solutions that allow you to use NVMe commands on top of a network fabric. There is nothing wrong with that, they are just not standardized.
RDMA-Based NVMe-oF
What is RDMA?
Direct Memory Access (DMA) is an ability of a device to access host memory directly, without the intervention of the CPU. Then, Remote Direct Memory Access (RDMA) is the ability of accessing (read, write) memory on a remote machine without interrupting the processing of the CPU(s) on that system.
This short video, from the RoCE Initiative, explains pretty well the concept of RDMA over Fabric and RDMA over Converged Ethernet.
RDMA Main Advantages
- Zero-copy – applications can perform data transfers without the involvement of the network software stack. Data is sent and received directly to the buffers without being copied between the network layers.
- Kernel bypass – applications can perform data transfers directly from user-space without kernel involvement.
- No CPU involvement – applications can access remote memory without consuming any CPU time in the remote server. The remote memory server will be read without any intervention from the remote process (or processor). Moreover, the caches of the remote CPU will not be filled with the accessed memory content.
How to use RDMA?
In order to use RDMA, you need a network adapter that has RDMA capability: A RDMA-capable Ethernet NICs (rNICs), like Broadcom NetXtreme E-Series, Marvell/Cavium FastLinQ or Nvidia/Mellanox Connect-X series. Or, an InfiniBand Host Channel Adapter (HCA) in the InfiniBand world (again Nvidia/Mellanox Connect-X, for example). And as you can deduce from what is written above, the link layer protocol of the network can be either Ethernet or InfiniBand. Both can transfer the RDMA-based applications.
RDMA is supported in-box on the operating systems Linux, Windows, and VMware. On other Operating Systems, or for advanced features, you may need to download and install the relevant driver package and configure it accordingly.
Varieties of RDMA-based NVMe-oF
Now that we’ve seen that RDMA is one of the three options for transporting NVMe over a network fabric, let’s see the three varieties of RDMA:
- InfiniBand – InfiniBand network architecture supports RDMA natively.
- RoCE (RDMA over Converged Ethernet, pronounced “Rocky”) – Basically, this is the implementation of RDMA over an Ethernet network. It does this by an encapsulation of an InfiniBand transport packet over Ethernet. There are two different RoCE versions:
- RoCEv1 – Ethernet link layer protocol (Ethertype 0x8915) that allows communication between any two hosts in the same Ethernet broadcast domain. So, layer-2 only, not routable.
- RoCEv2 – Enhances RoCEv1 with a UDP/IP (IPv4 or IPv6) header and so adds layer-3 routability. NVMe/RoCEv2 use UDP destination port 4791 by default.
Here is a representation of the RoCEv1 and v2 headers (source Wikipedia):
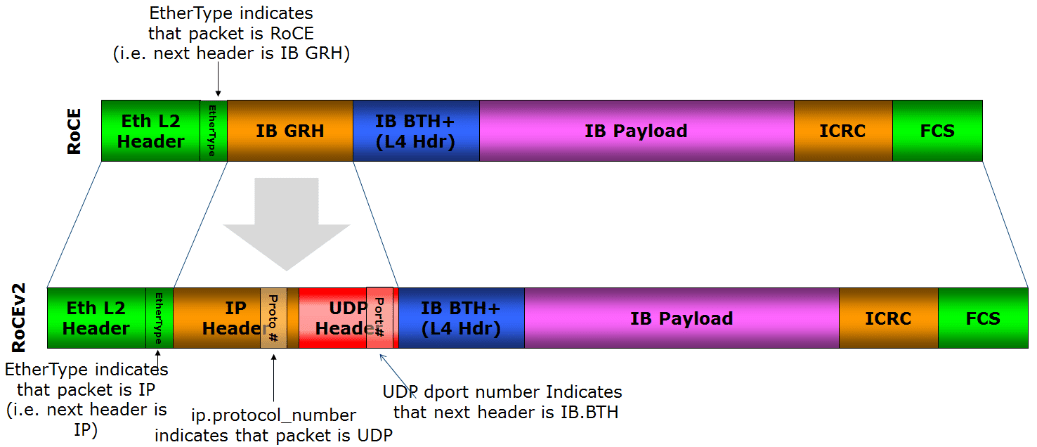
(click on the image to see a larger version)
- iWARP (Internet Wide-Area RDMA Protocol) – Layered on IETF-standard congestion-aware protocols such as TCP and SCTP. With offloaded TCP/IP flow control and management.
Even iWARP and RoCE are both using the same RDMA software verbs and the same kind of Ethernet RDMA-NIC (rNICs), they cannot talk RDMA to each other because of layer-3/layer-4 differences. Today, it seems that RoCEv2 is the most popular vendor option.
NVMe-oF Network Requirements
Protocols requirements
Based on what we have seen above, there are different requirements depending on the chosen NVMe-oF solution:
- Dedicated Networks
- NVMe/IB – uses RDMA over an InfiniBand network. Very popular in the high-performance computing (HPC) world. Unless you work in this field or perhaps in the stock market, you probably do not have an InfiniBand network in your data center.
- NVMe/FC – requires a generation 5 or 6 Fibre Channel network. It doesn’t use RDMA. Network engineers who have already FC networks and switching infrastructure in their data centers can continue to use these devoted resources as the transport for NVMe-oF. However, typical FC deployed speeds of 4, 16 or 32 Gbps may be insufficient to really take advantage of the performance increase available in NVMe devices.
- Shared or Converged Ethernet Networks
- Layer-2 only
- NVMe/FC (with FCoE) – it uses an Ethernet/FC shared network infrastructure. FCoE is not routable at the IP layer and it doesn’t use RDMA. FCoE have the same requirements and advantages of an FC network, but you lost the predictability of the network on the shared Ethernet part of the infrastructure. I will talk about network predictability below.
- Layer-3 capable
- NVMe/TCP – uses an Ethernet network with TCP/IP transport, but it doesn’t use RDMA. NVMe/TCP seems one of the most economical solutions, since Ethernet fabrics are cheaper than FC infrastructures, and simplest to implement. And since NVMe/TCP is naturally routable, the servers and their storage bays can communicate through an existing Ethernet data-center network, without the need for dedicated FC switches and HBAs. But, NVMe/TCP suffers from disadvantages: the most important is that it uses the server’s computing power, which is no longer fully available for running common applications. One of the most CPU-intensive TCP operations is the calculation of the parity code (checksum) of each packet. Another disadvantage is that it induces more latency in transfers than other NVMe-over-Fabrics protocols. This problem is due in particular to the need to maintain several copies of data in the flows in order to avoid packet loss at the routing level. Keeping a very low latency is also very important (see below).
- NVMe/iWARP – uses a shared Ethernet network, and RDMA over TCP.
- NVMe/RoCEv2 – uses a shared Ethernet network, and RDMA over UDP.
- Layer-2 only
Transport requirements: lossy vs lossless transport
In terms of the need for lossy vs lossless transport on an Ethernet fabric, as we saw above, RDMA is a memory-to-memory transport mechanism between two devices, so in theory it cannot tolerate any packet loss. But, since iWARP is based on the TCP protocol – as well as NVMe/TCP – it can tolerate packet drops in the transport and then some TCP retransmit, so NVMe/iWARP and NVMe/TCP can be transported over a lossy network.
RoCE, on the other hand, uses UDP, which cannot benefit from acknowledgements and retransmissions like TCP does. Moreover, from the RoCEv2 specifications, you should use a lossless fabric. But, inside the RoCE protocol there is a mechanism to protect against packet loss: upon packet drop, a NACK control packet with the specific packet sequence number (PSN) is sent to the sender in order for it to re-transmit the packet. It is therefore not entirely true to say that RoCE requires a lossless network transport (lossless Ethernet). RoCE can operate in either lossless or lossy network.
Other network information about NVMe-oF
Here is a series of information that I have gathered from discussions with experts and technical seminars. Please keep in mind that the information below may vary depending of your needs and may already be obsolete after a few months.
- Dedicated vs Shared Ethernet – The main disadvantage of using a dedicated network, IB or FC, compared to a shared Ethernet solution is the price. It includes of course the need to maintain the dedicated network itself, but also the personnel and their skills and knowledge. On the other hand, the great advantage of the dedicated network is this network is predictable. You know exactly what is on your network, the expected traffic, latency, and so on. Sometimes, especially when it comes to storage, predictability is more important than anything else.
- NVMe/TCP vs iWARP vs RoCEv2 – the offload capabilities of RDMA using rNICs can give a significant performance boost comparing to NVMe/TCP, by reducing protocol processing overhead and expensive memory copies. But, as with all converged infrastructures, bandwidth is the key. No over-subscription and you need to closely manage and control inbound traffic, queues and traffic prioritization. This is even truer with RoCE, which does not support (or almost) any packet loss.
- How far can we put our targets from our hosts – Since we can do Layer-3 routing, don’t think that you can put the storage far away from the servers, over an enterprise WAN link for example. No, generally speaking we try to keep the target as close as possible from the hosts. The NVMe has very strict end-to-end latency requirements, and unless the network infrastructure is specifically designed to provide very low latency, the NVMe may not operate properly.
- What is an acceptable latency – Each application, databases or heart-bit protocols have a known latency or RTT budget. You should base your question on this: what protocol are you using and what are the latency requirements. On top of that, as written above, we try to keep the target as close as possible from the hosts.
- Layer-2 vs Layer-3 for storage fabric – According to some storage experts, best practices for storage, especially bloc storage, is not to route traffic, mostly because of latency reasons. However, today’s modern data-center networks are no longer based on layer-2 (STP + MLAG) but on the contrary on a layer-3 underlay with an overlay (VXLAN or similar) layer. This sentence is therefore a bit contradictory.
If after this post you ask yourself questions like: “Should I build a dedicated storage network or use a Converged Ethernet network?” or “On an Ethernet network, should I use NVMe/TCP, or NVMe/RDMA and then RoCEv1 vs RoCEv2 vs iWARP?” and “What about latency, scaling?”
I suggest you check out Dr. J Metz’s session on Cisco Live: The Networking Implications of NVMe over Fabrics (NVMe-oF) – BRKDCN-2729
RDMA over Converged Ethernet (RoCE)
References / Read More
- NVMexpress.org – The home page of NVM express
- NVMe for Absolute Beginners – The Cisco Blog of J Metz
- NetCraftsmen: WHAT IS NVME AND HOW DOES IT IMPACT MY NETWORK? From Peter Welcher
- NVMe BrightTalk webinar – The Performance Impact of NVMe and NVMe over Fabrics
- PacketPushers: Ethernet Network Design For NVMe Over Fabrics With Dr. J Metz (Video)
- J Metz SNIA Presentation: NVMe Over Fabrics (mentions DCTCP)
- Network World article: NVMeoF Storage Disruption
- CiscoLive On Demand: Recent NVMe Presentations
- The RoCE Initiative
agree!
This blog is an astonishing one. It is very descriptive and such a reliable article. It provides facts like the specifications and it answers all the possible questions of the people. Indeed a great blog.